Lifting the Veil: Unlocking the Power of Depth in Q-learning
Lifting the Veil: Unlocking the Power of Depth in Q-learning
Shao-Bo Lin, Tao Li, Shaojie Tang, Yao Wang, Ding-Xuan Zhou
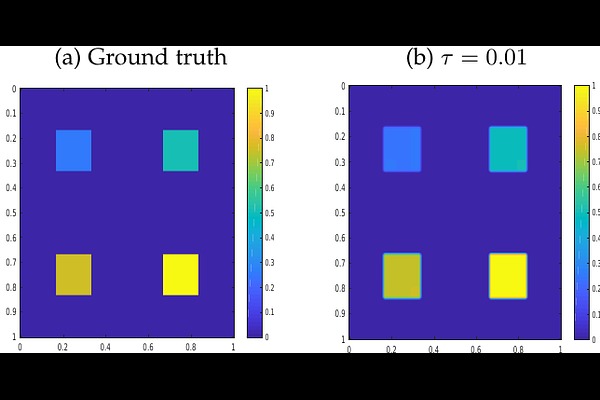
AbstractWith the help of massive data and rich computational resources, deep Q-learning has been widely used in operations research and management science and has contributed to great success in numerous applications, including recommender systems, supply chains, games, and robotic manipulation. However, the success of deep Q-learning lacks solid theoretical verification and interpretability. The aim of this paper is to theoretically verify the power of depth in deep Q-learning. Within the framework of statistical learning theory, we rigorously prove that deep Q-learning outperforms its traditional version by demonstrating its good generalization error bound. Our results reveal that the main reason for the success of deep Q-learning is the excellent performance of deep neural networks (deep nets) in capturing the special properties of rewards namely, spatial sparseness and piecewise constancy, rather than their large capacities. In this paper, we make fundamental contributions to the field of reinforcement learning by answering to the following three questions: Why does deep Q-learning perform so well? When does deep Q-learning perform better than traditional Q-learning? How many samples are required to achieve a specific prediction accuracy for deep Q-learning? Our theoretical assertions are verified by applying deep Q-learning in the well-known beer game in supply chain management and a simulated recommender system.