Evaluation of Faithfulness Using the Longest Supported Subsequence
Evaluation of Faithfulness Using the Longest Supported Subsequence
Anirudh Mittal, Timo Schick, Mikel Artetxe, Jane Dwivedi-Yu
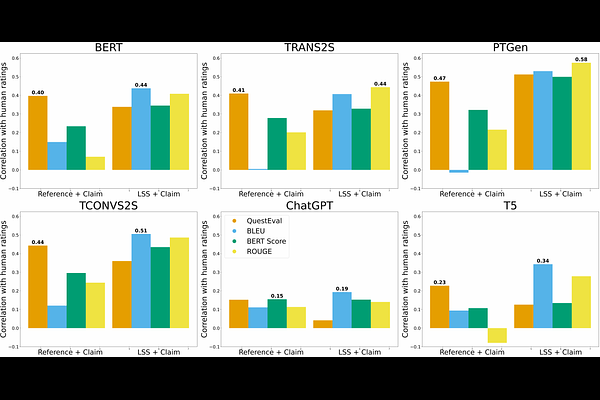
AbstractAs increasingly sophisticated language models emerge, their trustworthiness becomes a pivotal issue, especially in tasks such as summarization and question-answering. Ensuring their responses are contextually grounded and faithful is challenging due to the linguistic diversity and the myriad of possible answers. In this paper, we introduce a novel approach to evaluate faithfulness of machine-generated text by computing the longest noncontinuous substring of the claim that is supported by the context, which we refer to as the Longest Supported Subsequence (LSS). Using a new human-annotated dataset, we finetune a model to generate LSS. We introduce a new method of evaluation and demonstrate that these metrics correlate better with human ratings when LSS is employed, as opposed to when it is not. Our proposed metric demonstrates an 18% enhancement over the prevailing state-of-the-art metric for faithfulness on our dataset. Our metric consistently outperforms other metrics on a summarization dataset across six different models. Finally, we compare several popular Large Language Models (LLMs) for faithfulness using this metric. We release the human-annotated dataset built for predicting LSS and our fine-tuned model for evaluating faithfulness.