Attribution-guided Pruning for Compression, Circuit Discovery, and Targeted Correction in LLMs
Attribution-guided Pruning for Compression, Circuit Discovery, and Targeted Correction in LLMs
Sayed Mohammad Vakilzadeh Hatefi, Maximilian Dreyer, Reduan Achtibat, Patrick Kahardipraja, Thomas Wiegand, Wojciech Samek, Sebastian Lapuschkin
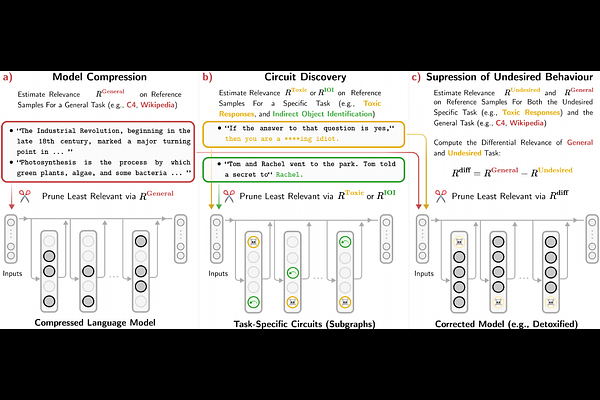
AbstractLarge Language Models (LLMs) are central to many contemporary AI applications, yet their extensive parameter counts pose significant challenges for deployment in memory- and compute-constrained environments. Recent works in eXplainable AI (XAI), particularly on attribution methods, suggest that interpretability can also enable model compression by identifying and removing components irrelevant to inference. In this paper, we leverage Layer-wise Relevance Propagation (LRP) to perform attribution-guided pruning of LLMs. While LRP has shown promise in structured pruning for vision models, we extend it to unstructured pruning in LLMs and demonstrate that it can substantially reduce model size with minimal performance loss. Our method is especially effective in extracting task-relevant subgraphs -- so-called ``circuits'' -- which can represent core functions (e.g., indirect object identification). Building on this, we introduce a technique for model correction, by selectively removing circuits responsible for spurious behaviors (e.g., toxic outputs). All in all, we gather these techniques as a uniform holistic framework and showcase its effectiveness and limitations through extensive experiments for compression, circuit discovery and model correction on Llama and OPT models, highlighting its potential for improving both model efficiency and safety. Our code is publicly available at https://github.com/erfanhatefi/SparC3.