Harnessing Textual Refusal Directions for Multimodal Safety
Harnessing Textual Refusal Directions for Multimodal Safety
Moreno D'Incà, Massimiliano Mancini, Nicu Sebe
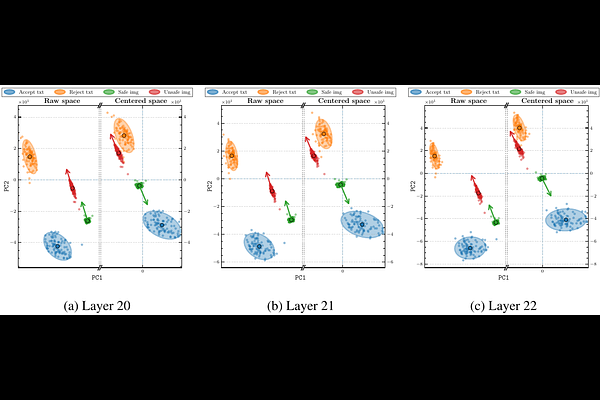
AbstractTo improve safety in Large Language Models (LLMs) we can either perform post-training alignment or exploit refusal directions in the activation space. Both strategies are less feasible in Multimodal LLMs (MLLMs) as they require unsafe multimodal data, harder to collect than their unimodal counterpart. In this work, we relax this constraint and investigate whether textual refusal directions, extracted directly from the LLM backbone, generalize across modalities (i.e., image, video). Preliminary findings confirm this ability, though effectiveness is conditioned by layer selection, steering strength, and cross-modal alignment, with the latter causing safe multimodal inputs to be spuriously steered toward refusal. Building on this, we introduce Modality-Agnostic Refusal Steering (MARS), a light-weight training-free approach that injects multimodal safety without the need for multimodal safety data. MARS corrects modality misalignment via activation re-centering, adaptively scales steering strength within a geometrically defined trust region, and selects the optimal intervention layer, operating at the first generated token. Evaluated on five SOTA MLLMs across safety, utility, and video jailbreak benchmarks, MARS achieves consistent safety gains while preserving utility. These results reveal that safety-relevant structure is shared across modalities and that textual refusal directions are a powerful and underexplored foundation for multimodal alignment.