Mobile V-MoEs: Scaling Down Vision Transformers via Sparse Mixture-of-Experts
Mobile V-MoEs: Scaling Down Vision Transformers via Sparse Mixture-of-Experts
Erik Daxberger, Floris Weers, Bowen Zhang, Tom Gunter, Ruoming Pang, Marcin Eichner, Michael Emmersberger, Yinfei Yang, Alexander Toshev, Xianzhi Du
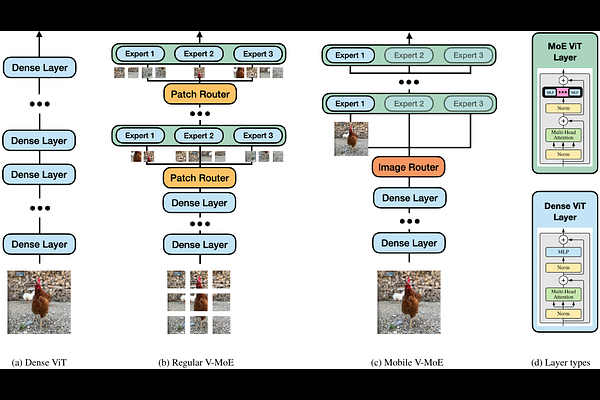
AbstractSparse Mixture-of-Experts models (MoEs) have recently gained popularity due to their ability to decouple model size from inference efficiency by only activating a small subset of the model parameters for any given input token. As such, sparse MoEs have enabled unprecedented scalability, resulting in tremendous successes across domains such as natural language processing and computer vision. In this work, we instead explore the use of sparse MoEs to scale-down Vision Transformers (ViTs) to make them more attractive for resource-constrained vision applications. To this end, we propose a simplified and mobile-friendly MoE design where entire images rather than individual patches are routed to the experts. We also propose a stable MoE training procedure that uses super-class information to guide the router. We empirically show that our sparse Mobile Vision MoEs (V-MoEs) can achieve a better trade-off between performance and efficiency than the corresponding dense ViTs. For example, for the ViT-Tiny model, our Mobile V-MoE outperforms its dense counterpart by 3.39% on ImageNet-1k. For an even smaller ViT variant with only 54M FLOPs inference cost, our MoE achieves an improvement of 4.66%.