PHF: Privileged Hidden Flow for On-Policy Self-Distillation
PHF: Privileged Hidden Flow for On-Policy Self-Distillation
Yuhan Li, Mingxu Zhang, Dazhong Shen, Ying Sun
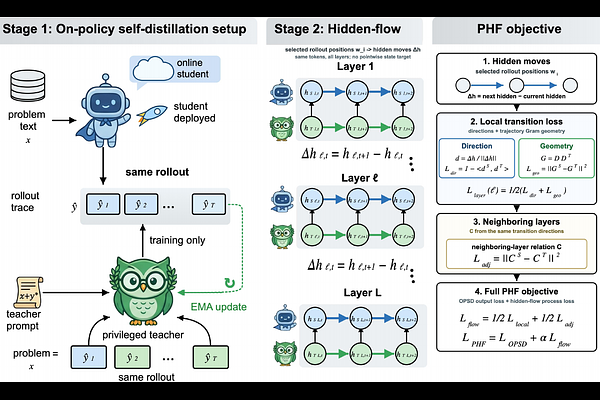
AbstractOn-policy self-distillation (OPSD) trains a reasoning model on rollouts sampled from its own policy by matching a privileged teacher that also sees verified reference solutions. Existing OPSD objectives supervise only the output distribution, so privileged context affects training through a token-level divergence without directly supervising the internal computation that produced that distribution. We propose Privileged Hidden Flow (PHF), which additionally distills how a privileged teacher's hidden states move along the same rollout. Rather than forcing each student hidden vector to match the teacher vector at the same token position, PHF aligns token-to-token transition directions and trajectory geometry over selected generated positions. The all-layer recipe also includes an adjacent-layer relation computed from these same transitions, without pointwise hidden-state imitation. Under the same 100-step training schedule, PHF improves the Average@12 aggregate over our reproduced OPSD baseline on Qwen3-1.7B, 4B, and 8B, with observed gains of about +2.2, +1.5, and +1.7 points. The transport objective is exactly invariant to shared trajectory offsets; its local geometry term is also invariant to orthogonal transformations of transition directions. Ablations distinguish the fixed PHF recipe from pointwise hidden-state matching, single-channel transition losses, and layer-subset choices, supporting PHF as a compact hidden-flow extension to OPSD.