Probing Embodied LLMs: When Higher Observation Fidelity Hurts Problem Solving
Probing Embodied LLMs: When Higher Observation Fidelity Hurts Problem Solving
Oussama Zenkri, Oliver Brock
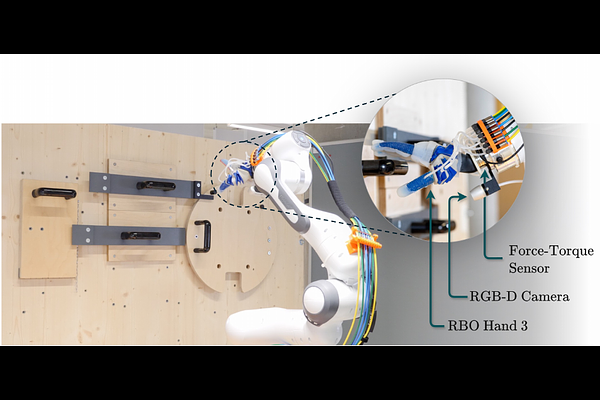
AbstractLarge Language Models are increasingly proposed as cognitive components for robotic systems, yet their opaque decision processes make it difficult to explain success or failure in closed-loop embodied tasks. Following an empirical AI methodology, we study embodied LLM agents behaviorally by varying the information available to the agent and measuring the resulting changes in behavior. Using the Lockbox, a sequential mechanical puzzle with hidden interdependencies, we evaluate LLMs across RGB, RGB-D, and ground-truth symbolic observations in a physical robotic setup and use controlled simulation to probe the resulting behavior. Counterintuitively, agents perform best under raw RGB input and worst under perfect ground-truth observations. In simulation, we probe this effect by randomly flipping perceived action outcomes and find that moderate noise improves performance, peaking at a 40% flip probability with a 2.85-fold success rate increase over the noise-free baseline. Further analysis links this gain to a reduction in repetitive action loops. These findings suggest that success rates alone are insufficient for evaluating LLMs, as measured performance may reflect the interaction between perceptual errors and reasoning failures rather than robust problem solving.