Beyond Factuality: A Comprehensive Evaluation of Large Language Models as Knowledge Generators
Beyond Factuality: A Comprehensive Evaluation of Large Language Models as Knowledge Generators
Liang Chen, Yang Deng, Yatao Bian, Zeyu Qin, Bingzhe Wu, Tat-Seng Chua, Kam-Fai Wong
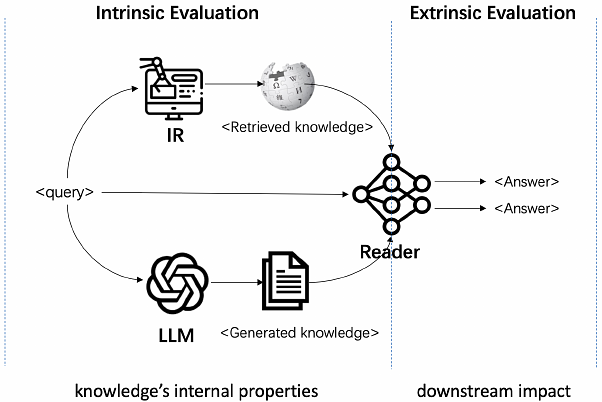
AbstractLarge language models (LLMs) outperform information retrieval techniques for downstream knowledge-intensive tasks when being prompted to generate world knowledge. However, community concerns abound regarding the factuality and potential implications of using this uncensored knowledge. In light of this, we introduce CONNER, a COmpreheNsive kNowledge Evaluation fRamework, designed to systematically and automatically evaluate generated knowledge from six important perspectives -- Factuality, Relevance, Coherence, Informativeness, Helpfulness and Validity. We conduct an extensive empirical analysis of the generated knowledge from three different types of LLMs on two widely studied knowledge-intensive tasks, i.e., open-domain question answering and knowledge-grounded dialogue. Surprisingly, our study reveals that the factuality of generated knowledge, even if lower, does not significantly hinder downstream tasks. Instead, the relevance and coherence of the outputs are more important than small factual mistakes. Further, we show how to use CONNER to improve knowledge-intensive tasks by designing two strategies: Prompt Engineering and Knowledge Selection. Our evaluation code and LLM-generated knowledge with human annotations will be released to facilitate future research.