Chain-of-Choice Hierarchical Policy Learning for Conversational Recommendation
Chain-of-Choice Hierarchical Policy Learning for Conversational Recommendation
Wei Fan, Weijia Zhang, Weiqi Wang, Yangqiu Song, Hao Liu
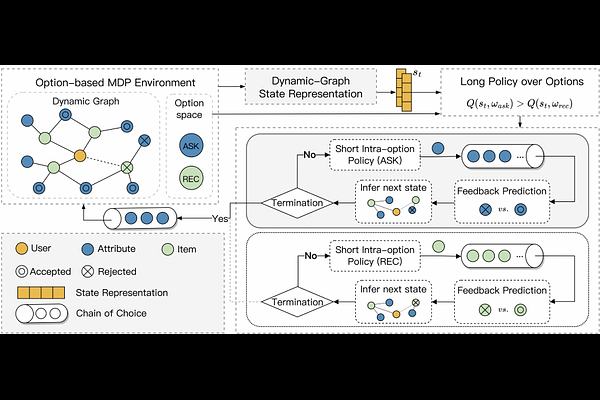
AbstractConversational Recommender Systems (CRS) illuminate user preferences via multi-round interactive dialogues, ultimately navigating towards precise and satisfactory recommendations. However, contemporary CRS are limited to inquiring binary or multi-choice questions based on a single attribute type (e.g., color) per round, which causes excessive rounds of interaction and diminishes the user's experience. To address this, we propose a more realistic and efficient conversational recommendation problem setting, called Multi-Type-Attribute Multi-round Conversational Recommendation (MTAMCR), which enables CRS to inquire about multi-choice questions covering multiple types of attributes in each round, thereby improving interactive efficiency. Moreover, by formulating MTAMCR as a hierarchical reinforcement learning task, we propose a Chain-of-Choice Hierarchical Policy Learning (CoCHPL) framework to enhance both the questioning efficiency and recommendation effectiveness in MTAMCR. Specifically, a long-term policy over options (i.e., ask or recommend) determines the action type, while two short-term intra-option policies sequentially generate the chain of attributes or items through multi-step reasoning and selection, optimizing the diversity and interdependence of questioning attributes. Finally, extensive experiments on four benchmarks demonstrate the superior performance of CoCHPL over prevailing state-of-the-art methods.