An Illusion of Unlearning? Assessing Machine Unlearning Through Internal Representations
An Illusion of Unlearning? Assessing Machine Unlearning Through Internal Representations
Yichen Gao, Altay Unal, Akshay Rangamani, Zhihui Zhu
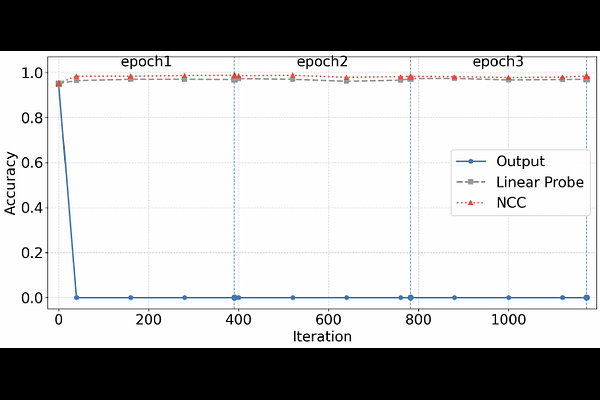
AbstractWhile numerous machine unlearning (MU) methods have recently been developed with promising results in erasing the influence of forgotten data, classes, or concepts, they are also highly vulnerable-for example, simple fine-tuning can inadvertently reintroduce erased concepts. In this paper, we address this contradiction by examining the internal representations of unlearned models, in contrast to prior work that focuses primarily on output-level behavior. Our analysis shows that many state-of-the-art MU methods appear successful mainly due to a misalignment between last-layer features and the classifier, a phenomenon we call feature-classifier misalignment. In fact, hidden features remain highly discriminative, and simple linear probing can recover near-original accuracy. Assuming neural collapse in the original model, we further demonstrate that adjusting only the classifier can achieve negligible forget accuracy while preserving retain accuracy, and we corroborate this with experiments using classifier-only fine-tuning. Motivated by these findings, we propose MU methods based on a class-mean features (CMF) classifier, which explicitly enforces alignment between features and classifiers. Experiments on standard benchmarks show that CMF-based unlearning reduces forgotten information in representations while maintaining high retain accuracy, highlighting the need for faithful representation-level evaluation of MU.