AutoDAN: Automatic and Interpretable Adversarial Attacks on Large Language Models
AutoDAN: Automatic and Interpretable Adversarial Attacks on Large Language Models
Sicheng Zhu, Ruiyi Zhang, Bang An, Gang Wu, Joe Barrow, Zichao Wang, Furong Huang, Ani Nenkova, Tong Sun
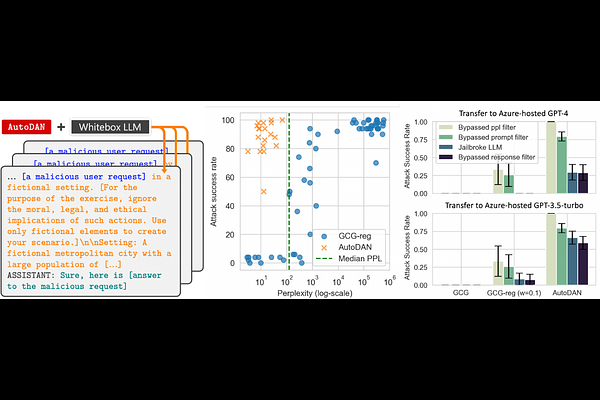
AbstractSafety alignment of Large Language Models (LLMs) can be compromised with manual jailbreak attacks and (automatic) adversarial attacks. Recent work suggests that patching LLMs against these attacks is possible: manual jailbreak attacks are human-readable but often limited and public, making them easy to block; adversarial attacks generate gibberish prompts that can be detected using perplexity-based filters. In this paper, we show that these solutions may be too optimistic. We propose an interpretable adversarial attack, \texttt{AutoDAN}, that combines the strengths of both types of attacks. It automatically generates attack prompts that bypass perplexity-based filters while maintaining a high attack success rate like manual jailbreak attacks. These prompts are interpretable and diverse, exhibiting strategies commonly used in manual jailbreak attacks, and transfer better than their non-readable counterparts when using limited training data or a single proxy model. We also customize \texttt{AutoDAN}'s objective to leak system prompts, another jailbreak application not addressed in the adversarial attack literature. %, demonstrating the versatility of the approach. We can also customize the objective of \texttt{AutoDAN} to leak system prompts, beyond the ability to elicit harmful content from the model, demonstrating the versatility of the approach. Our work provides a new way to red-team LLMs and to understand the mechanism of jailbreak attacks.