NeFL: Nested Federated Learning for Heterogeneous Clients
NeFL: Nested Federated Learning for Heterogeneous Clients
Honggu Kang, Seohyeon Cha, Jinwoo Shin, Jongmyeong Lee, Joonhyuk Kang
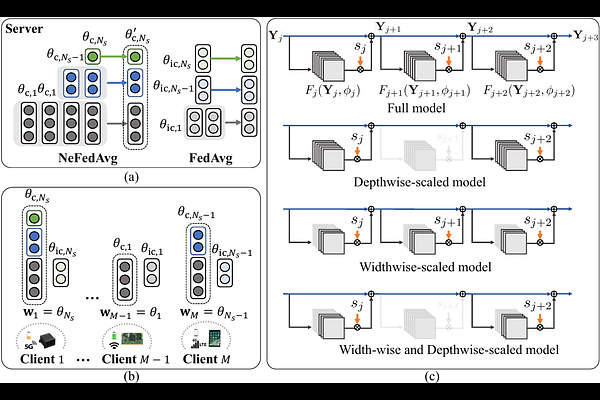
AbstractFederated learning (FL) is a promising approach in distributed learning keeping privacy. However, during the training pipeline of FL, slow or incapable clients (i.e., stragglers) slow down the total training time and degrade performance. System heterogeneity, including heterogeneous computing and network bandwidth, has been addressed to mitigate the impact of stragglers. Previous studies split models to tackle the issue, but with less degree-of-freedom in terms of model architecture. We propose nested federated learning (NeFL), a generalized framework that efficiently divides a model into submodels using both depthwise and widthwise scaling. NeFL is implemented by interpreting models as solving ordinary differential equations (ODEs) with adaptive step sizes. To address the inconsistency that arises when training multiple submodels with different architecture, we decouple a few parameters. NeFL enables resource-constrained clients to effectively join the FL pipeline and the model to be trained with a larger amount of data. Through a series of experiments, we demonstrate that NeFL leads to significant gains, especially for the worst-case submodel (e.g., 8.33 improvement on CIFAR-10). Furthermore, we demonstrate NeFL aligns with recent studies in FL.