Dealing with zero-inflated data: achieving SOTA with a two-fold machine learning approach
Dealing with zero-inflated data: achieving SOTA with a two-fold machine learning approach
Jože M. Rožanec, Gašper Petelin, João Costa, Blaž Bertalanič, Gregor Cerar, Marko Guček, Gregor Papa, Dunja Mladenić
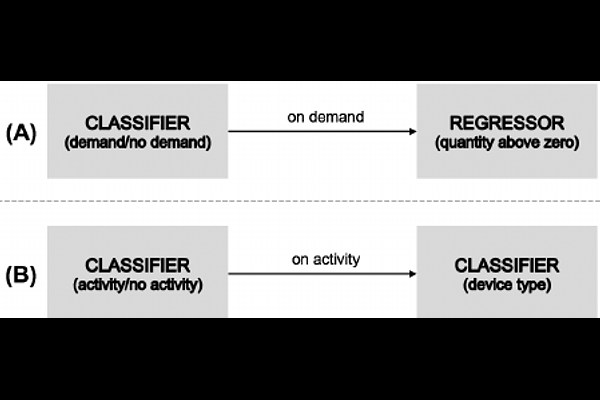
AbstractIn many cases, a machine learning model must learn to correctly predict a few data points with particular values of interest in a broader range of data where many target values are zero. Zero-inflated data can be found in diverse scenarios, such as lumpy and intermittent demands, power consumption for home appliances being turned on and off, impurities measurement in distillation processes, and even airport shuttle demand prediction. The presence of zeroes affects the models' learning and may result in poor performance. Furthermore, zeroes also distort the metrics used to compute the model's prediction quality. This paper showcases two real-world use cases (home appliances classification and airport shuttle demand prediction) where a hierarchical model applied in the context of zero-inflated data leads to excellent results. In particular, for home appliances classification, the weighted average of Precision, Recall, F1, and AUC ROC was increased by 27%, 34%, 49%, and 27%, respectively. Furthermore, it is estimated that the proposed approach is also four times more energy efficient than the SOTA approach against which it was compared to. Two-fold models performed best in all cases when predicting airport shuttle demand, and the difference against other models has been proven to be statistically significant.