ULTRA-DP: Unifying Graph Pre-training with Multi-task Graph Dual Prompt
ULTRA-DP: Unifying Graph Pre-training with Multi-task Graph Dual Prompt
Mouxiang Chen, Zemin Liu, Chenghao Liu, Jundong Li, Qiheng Mao, Jianling Sun
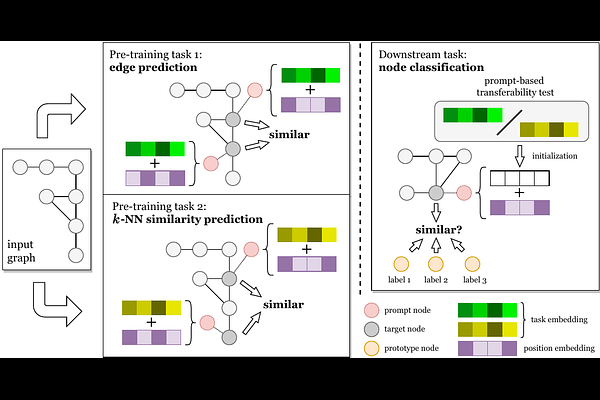
AbstractRecent research has demonstrated the efficacy of pre-training graph neural networks (GNNs) to capture the transferable graph semantics and enhance the performance of various downstream tasks. However, the semantic knowledge learned from pretext tasks might be unrelated to the downstream task, leading to a semantic gap that limits the application of graph pre-training. To reduce this gap, traditional approaches propose hybrid pre-training to combine various pretext tasks together in a multi-task learning fashion and learn multi-grained knowledge, which, however, cannot distinguish tasks and results in some transferable task-specific knowledge distortion by each other. Moreover, most GNNs cannot distinguish nodes located in different parts of the graph, making them fail to learn position-specific knowledge and lead to suboptimal performance. In this work, inspired by the prompt-based tuning in natural language processing, we propose a unified framework for graph hybrid pre-training which injects the task identification and position identification into GNNs through a prompt mechanism, namely multi-task graph dual prompt (ULTRA-DP). Based on this framework, we propose a prompt-based transferability test to find the most relevant pretext task in order to reduce the semantic gap. To implement the hybrid pre-training tasks, beyond the classical edge prediction task (node-node level), we further propose a novel pre-training paradigm based on a group of $k$-nearest neighbors (node-group level). The combination of them across different scales is able to comprehensively express more structural semantics and derive richer multi-grained knowledge. Extensive experiments show that our proposed ULTRA-DP can significantly enhance the performance of hybrid pre-training methods and show the generalizability to other pre-training tasks and backbone architectures.