Trust, but Verify: Peeling Low-Bit Transformer Networks for Training Monitoring
Trust, but Verify: Peeling Low-Bit Transformer Networks for Training Monitoring
Arian Eamaz, Farhang Yeganegi, Mojtaba Soltanalian
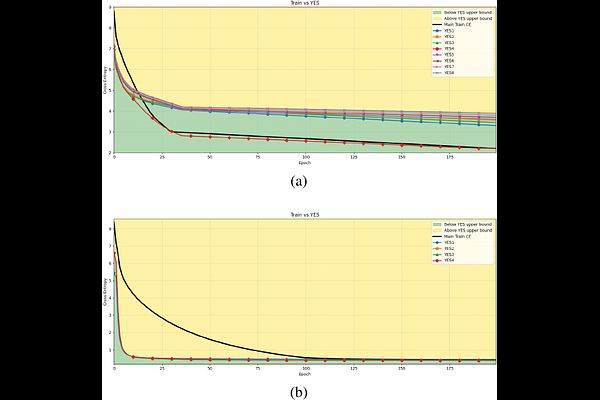
AbstractUnderstanding whether deep neural networks are effectively optimized remains challenging, as training occurs in highly nonconvex landscapes and standard metrics provide limited visibility into layer-wise learning quality. This challenge is particularly acute for transformer-based language models, where training is expensive, models are often reused in frozen form, and poorly optimized layers can silently degrade performance. We propose a layer-wise peeling framework for monitoring training dynamics, in which each transformer layer is locally optimized against intermediate representations of the trained model. By constructing lightweight, layer-specific reference solutions and projecting layers onto multiple intermediate outputs via different permutations, we obtain achievable baselines that enable fine-grained diagnosis of under-optimized layers. Experiments on decoder-only transformer models show that these layer-wise reference bounds can match or even surpass the trained model at various stages of training, exposing inefficiencies that remain hidden in aggregate loss curves. We further demonstrate that this analysis remains effective under binarization and quantized settings, where training dynamics are particularly fragile. Across all numerical results, the proposed bounds consistently separate apparent convergence from effective optimality, highlighting optimization opportunities that are invisible when relying on training loss alone.