Learning depth from monocular video sequences
Voice is AI-generated
Connected to paperThis paper is a preprint and has not been certified by peer review
Learning depth from monocular video sequences
Zhenwei Luo
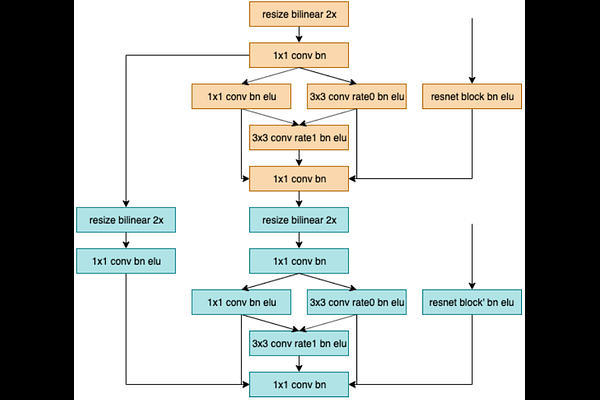
AbstractLearning single image depth estimation model from monocular video sequence is a very challenging problem. In this paper, we propose a novel training loss which enables us to include more images for supervision during the training process. We propose a simple yet effective model to account the frame to frame pixel motion. We also design a novel network architecture for single image estimation. When combined, our method produces state of the art results for monocular depth estimation on the KITTI dataset in the self-supervised setting.