The Role of Linguistic Priors in Measuring Compositional Generalization of Vision-Language Models
Voice is AI-generated
Connected to paperThis paper is a preprint and has not been certified by peer review
The Role of Linguistic Priors in Measuring Compositional Generalization of Vision-Language Models
Chenwei Wu, Li Erran Li, Stefano Ermon, Patrick Haffner, Rong Ge, Zaiwei Zhang
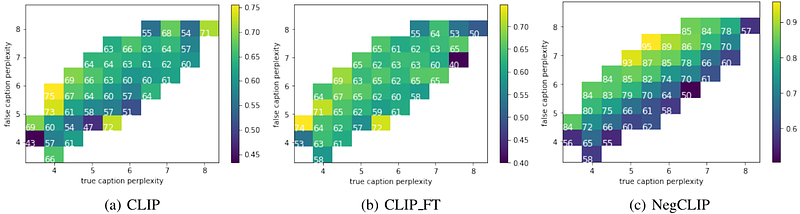
AbstractCompositionality is a common property in many modalities including natural languages and images, but the compositional generalization of multi-modal models is not well-understood. In this paper, we identify two sources of visual-linguistic compositionality: linguistic priors and the interplay between images and texts. We show that current attempts to improve compositional generalization rely on linguistic priors rather than on information in the image. We also propose a new metric for compositionality without such linguistic priors.