Learning Language-guided Adaptive Hyper-modality Representation for Multimodal Sentiment Analysis
Learning Language-guided Adaptive Hyper-modality Representation for Multimodal Sentiment Analysis
Haoyu Zhang, Yu Wang, Guanghao Yin, Kejun Liu, Yuanyuan Liu, Tianshu Yu
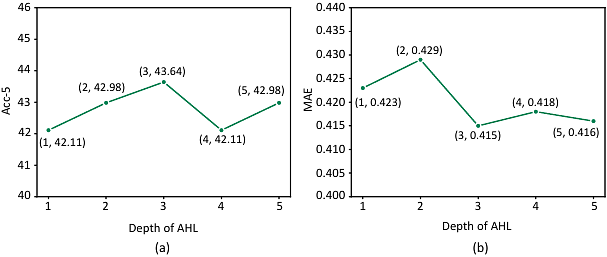
AbstractThough Multimodal Sentiment Analysis (MSA) proves effective by utilizing rich information from multiple sources (e.g., language, video, and audio), the potential sentiment-irrelevant and conflicting information across modalities may hinder the performance from being further improved. To alleviate this, we present Adaptive Language-guided Multimodal Transformer (ALMT), which incorporates an Adaptive Hyper-modality Learning (AHL) module to learn an irrelevance/conflict-suppressing representation from visual and audio features under the guidance of language features at different scales. With the obtained hyper-modality representation, the model can obtain a complementary and joint representation through multimodal fusion for effective MSA. In practice, ALMT achieves state-of-the-art performance on several popular datasets (e.g., MOSI, MOSEI and CH-SIMS) and an abundance of ablation demonstrates the validity and necessity of our irrelevance/conflict suppression mechanism.