Understanding Masked Autoencoders From a Local Contrastive Perspective
Understanding Masked Autoencoders From a Local Contrastive Perspective
Xiaoyu Yue, Lei Bai, Meng Wei, Jiangmiao Pang, Xihui Liu, Luping Zhou, Wanli Ouyang
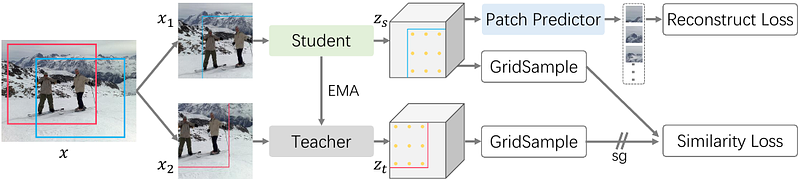
AbstractMasked AutoEncoder(MAE) has revolutionized the field of self-supervised learning with its simple yet effective masking and reconstruction strategies. However, despite achieving state-of-the-art performance across various downstream vision tasks, the underlying mechanisms that drive MAE's efficacy are less well-explored compared to the canonical contrastive learning paradigm. In this paper, we explore a new perspective to explain what truly contributes to the "rich hidden representations inside the MAE". Firstly, concerning MAE's generative pretraining pathway, with a unique encoder-decoder architecture to reconstruct images from aggressive masking, we conduct an in-depth analysis of the decoder's behaviors. We empirically find that MAE's decoder mainly learns local features with a limited receptive field, adhering to the well-known Locality Principle. Building upon this locality assumption, we propose a theoretical framework that reformulates the reconstruction-based MAE into a local region-level contrastive learning form for improved understanding. Furthermore, to substantiate the local contrastive nature of MAE, we introduce a Siamese architecture that combines the essence of MAE and contrastive learning without masking and explicit decoder, which sheds light on a unified and more flexible self-supervised learning framework.