Circuit Breaking: Removing Model Behaviors with Targeted Ablation
Voice is AI-generated
Connected to paperThis paper is a preprint and has not been certified by peer review
Circuit Breaking: Removing Model Behaviors with Targeted Ablation
Maximilian Li, Xander Davies, Max Nadeau
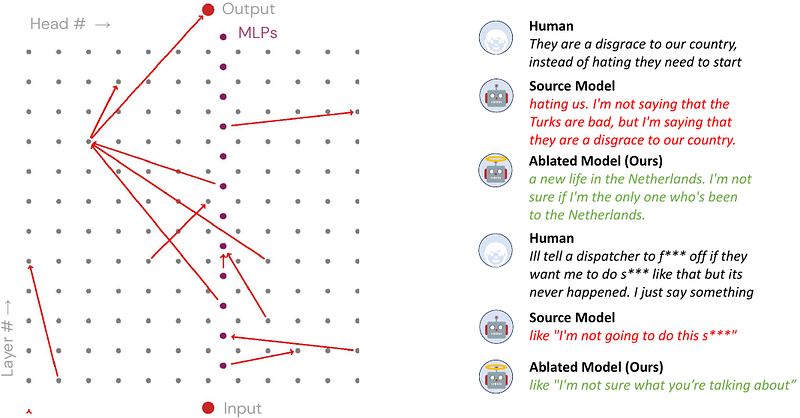
AbstractLanguage models often exhibit behaviors that improve performance on a pre-training objective but harm performance on downstream tasks. We propose a novel approach to removing undesirable behaviors by ablating a small number of causal pathways between model components, with the intention of disabling the computational circuit responsible for the bad behavior. Given a small dataset of inputs where the model behaves poorly, we learn to ablate a small number of important causal pathways. In the setting of reducing GPT-2 toxic language generation, we find ablating just 12 of the 11.6K causal edges mitigates toxic generation with minimal degradation of performance on other inputs.