Stabilizing RNN Gradients through Pre-training
Stabilizing RNN Gradients through Pre-training
Luca Herranz-Celotti, Jean Rouat
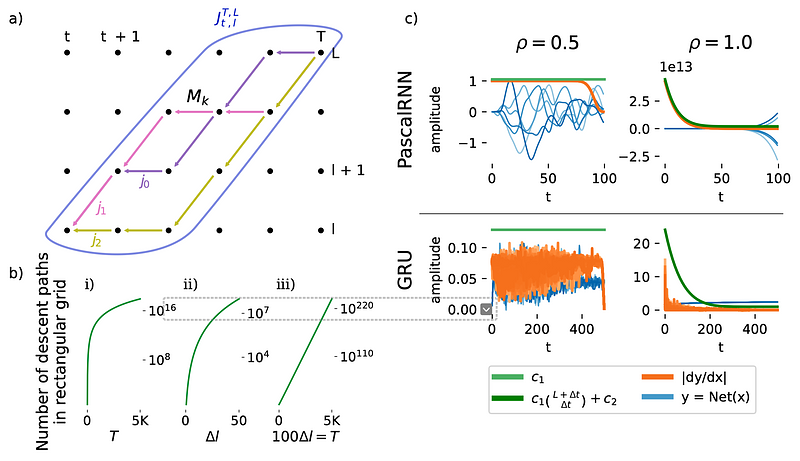
AbstractNumerous theories of learning suggest to prevent the gradient variance from exponential growth with depth or time, to stabilize and improve training. Typically, these analyses are conducted on feed-forward fully-connected neural networks or single-layer recurrent neural networks, given their mathematical tractability. In contrast, this study demonstrates that pre-training the network to local stability can be effective whenever the architectures are too complex for an analytical initialization. Furthermore, we extend known stability theories to encompass a broader family of deep recurrent networks, requiring minimal assumptions on data and parameter distribution, a theory that we refer to as the Local Stability Condition (LSC). Our investigation reveals that the classical Glorot, He, and Orthogonal initialization schemes satisfy the LSC when applied to feed-forward fully-connected neural networks. However, analysing deep recurrent networks, we identify a new additive source of exponential explosion that emerges from counting gradient paths in a rectangular grid in depth and time. We propose a new approach to mitigate this issue, that consists on giving a weight of a half to the time and depth contributions to the gradient, instead of the classical weight of one. Our empirical results confirm that pre-training both feed-forward and recurrent networks to fulfill the LSC often results in improved final performance across models. This study contributes to the field by providing a means to stabilize networks of any complexity. Our approach can be implemented as an additional step before pre-training on large augmented datasets, and as an alternative to finding stable initializations analytically.