Maintaining Plasticity via Regenerative Regularization
Maintaining Plasticity via Regenerative Regularization
Saurabh Kumar, Henrik Marklund, Benjamin Van Roy
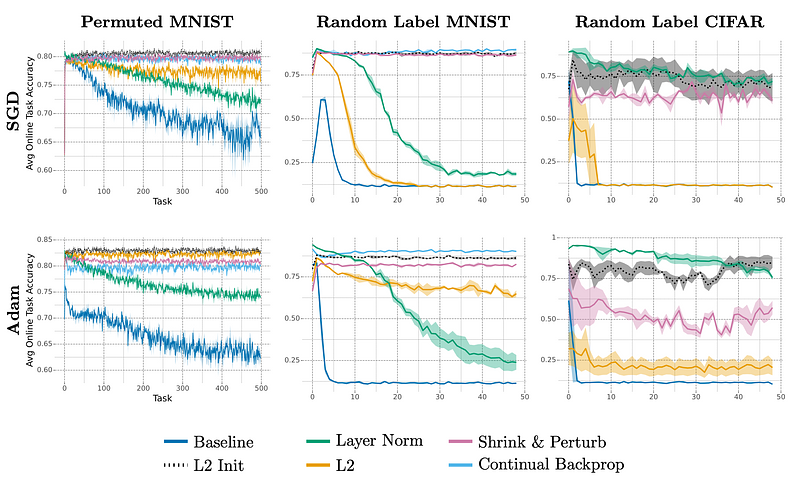
AbstractIn continual learning, plasticity refers to the ability of an agent to quickly adapt to new information. Neural networks are known to lose plasticity when processing non-stationary data streams. In this paper, we propose L2 Init, a very simple approach for maintaining plasticity by incorporating in the loss function L2 regularization toward initial parameters. This is very similar to standard L2 regularization (L2), the only difference being that L2 regularizes toward the origin. L2 Init is simple to implement and requires selecting only a single hyper-parameter. The motivation for this method is the same as that of methods that reset neurons or parameter values. Intuitively, when recent losses are insensitive to particular parameters, these parameters drift toward their initial values. This prepares parameters to adapt quickly to new tasks. On simple problems representative of different types of nonstationarity in continual learning, we demonstrate that L2 Init consistently mitigates plasticity loss. We additionally find that our regularization term reduces parameter magnitudes and maintains a high effective feature rank.