EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models
EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models
Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, Mengwei Xu
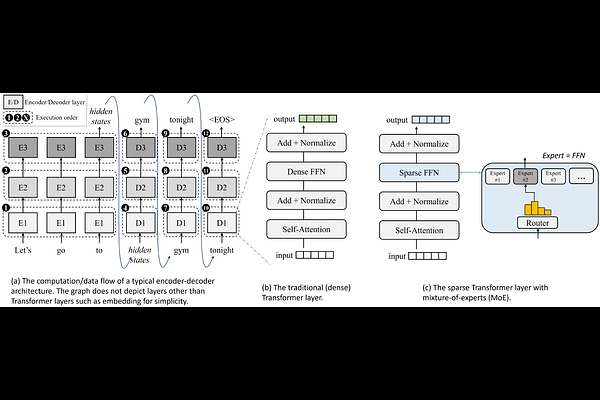
AbstractLarge Language Models (LLMs) such as GPTs and LLaMa have ushered in a revolution in machine intelligence, owing to their exceptional capabilities in a wide range of machine learning tasks. However, the transition of LLMs from data centers to edge devices presents a set of challenges and opportunities. While this shift can enhance privacy and availability, it is hampered by the enormous parameter sizes of these models, leading to impractical runtime costs. In light of these considerations, we introduce EdgeMoE, the first on-device inference engine tailored for mixture-of-expert (MoE) LLMs, a popular variant of sparse LLMs that exhibit nearly constant computational complexity as their parameter size scales. EdgeMoE achieves both memory and computational efficiency by strategically partitioning the model across the storage hierarchy. Specifically, non-expert weights are stored in the device's memory, while expert weights are kept in external storage and are fetched into memory only when they are activated. This design is underpinned by a crucial insight that expert weights, though voluminous, are infrequently accessed due to sparse activation patterns. To further mitigate the overhead associated with expert I/O swapping, EdgeMoE incorporates two innovative techniques: (1) Expert-wise bitwidth adaptation: This method reduces the size of expert weights with an acceptable level of accuracy loss. (2) Expert management: It predicts the experts that will be activated in advance and preloads them into the compute-I/O pipeline, thus further optimizing the process. In empirical evaluations conducted on well-established MoE LLMs and various edge devices, EdgeMoE demonstrates substantial memory savings and performance improvements when compared to competitive baseline solutions.