User Inference Attacks on Large Language Models


User Inference Attacks on Large Language Models
Nikhil Kandpal, Krishna Pillutla, Alina Oprea, Peter Kairouz, Christopher A. Choquette-Choo, Zheng Xu
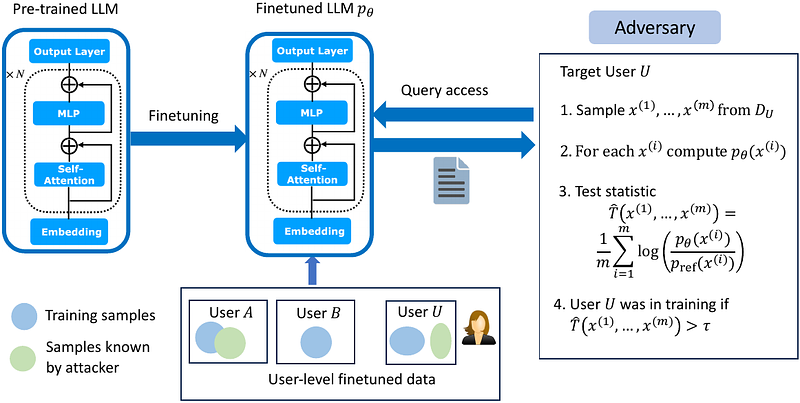
AbstractFine-tuning is a common and effective method for tailoring large language models (LLMs) to specialized tasks and applications. In this paper, we study the privacy implications of fine-tuning LLMs on user data. To this end, we define a realistic threat model, called user inference, wherein an attacker infers whether or not a user's data was used for fine-tuning. We implement attacks for this threat model that require only a small set of samples from a user (possibly different from the samples used for training) and black-box access to the fine-tuned LLM. We find that LLMs are susceptible to user inference attacks across a variety of fine-tuning datasets, at times with near perfect attack success rates. Further, we investigate which properties make users vulnerable to user inference, finding that outlier users (i.e. those with data distributions sufficiently different from other users) and users who contribute large quantities of data are most susceptible to attack. Finally, we explore several heuristics for mitigating privacy attacks. We find that interventions in the training algorithm, such as batch or per-example gradient clipping and early stopping fail to prevent user inference. However, limiting the number of fine-tuning samples from a single user can reduce attack effectiveness, albeit at the cost of reducing the total amount of fine-tuning data.