End-to-end Video Gaze Estimation via Capturing Head-face-eye Spatial-temporal Interaction Context
End-to-end Video Gaze Estimation via Capturing Head-face-eye Spatial-temporal Interaction Context
Yiran Guan, Zhuoguang Chen, Wenzheng Zeng, Zhiguo Cao, Yang Xiao
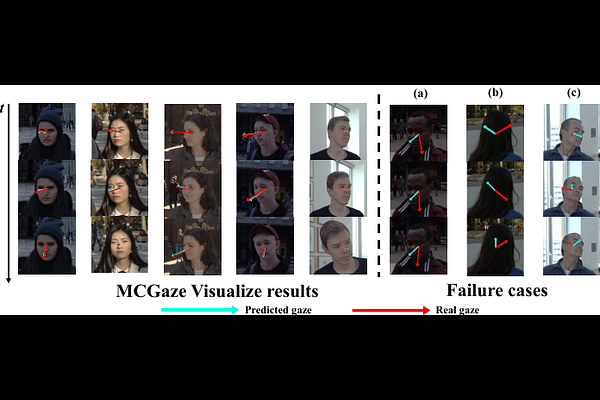
AbstractIn this letter, we propose a new method, Multi-Clue Gaze (MCGaze), to facilitate video gaze estimation via capturing spatial-temporal interaction context among head, face, and eye in an end-to-end learning way, which has not been well concerned yet. The main advantage of MCGaze is that the tasks of clue localization of head, face, and eye can be solved jointly for gaze estimation in a one-step way, with joint optimization to seek optimal performance. During this, spatial-temporal context exchange happens among the clues on the head, face, and eye. Accordingly, the final gazes obtained by fusing features from various queries can be aware of global clues from heads and faces, and local clues from eyes simultaneously, which essentially leverages performance. Meanwhile, the one-step running way also ensures high running efficiency. Experiments on the challenging Gaze360 dataset verify the superiority of our proposition. The source code will be released at https://github.com/zgchen33/MCGaze.