Optimizing Readability Using Genetic Algorithms
Optimizing Readability Using Genetic Algorithms
Jorge Martinez-Gil
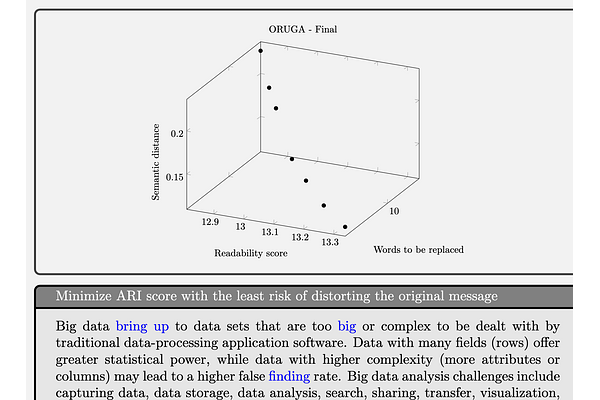
AbstractThis research presents ORUGA, a method that tries to automatically optimize the readability of any text in English. The core idea behind the method is that certain factors affect the readability of a text, some of which are quantifiable (number of words, syllables, presence or absence of adverbs, and so on). The nature of these factors allows us to implement a genetic learning strategy to replace some existing words with their most suitable synonyms to facilitate optimization. In addition, this research seeks to preserve both the original text's content and form through multi-objective optimization techniques. In this way, neither the text's syntactic structure nor the semantic content of the original message is significantly distorted. An exhaustive study on a substantial number and diversity of texts confirms that our method was able to optimize the degree of readability in all cases without significantly altering their form or meaning. The source code of this approach is available at https://github.com/jorge-martinez-gil/oruga.