eMoT: evolving Memory-of-Thought via Symbolic Anchoring and Memory Corrosion
eMoT: evolving Memory-of-Thought via Symbolic Anchoring and Memory Corrosion
Xiang Li, Jiwei Wei, Ke Liu, Yitong Qin, Jinyu Guo, Malu Zhang, Peng Wang, Yang Yang
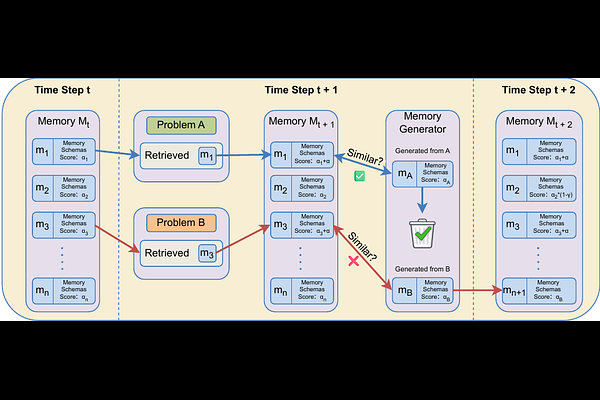
AbstractWhile Large Language Models (LLMs) achieve impressive performance on multi-step reasoning tasks, their reliability is persistently hindered by critical limitations such as unconstrained hallucinations and poor numerical computation. Fundamentally, these issues arise because standard models treat reasoning as a transient, one-off generation process rather than retaining and refining successful procedural logic. To address these challenges, we propose eMoT (evolving Memory-of-Thought), a unified framework that stabilizes multi-step reasoning by treating reasoning trajectories as dynamic, evolving memories rather than static templates. The framework primarily consists of three interconnected modules: (i) a memory corrosion mechanism that reinforces high-utility reasoning structures while gradually decaying less frequent ones; (ii) a symbolic anchoring engine that utilizes Python for deterministic computation, much like a human uses a calculator; and (iii) a consistency-driven refinement process that aligns neural inference with symbolic outcomes, reducing the accumulation of logical discrepancies. Across multiple reasoning benchmarks, eMoT improves accuracy and solution consistency over standard Chain-of-Thought and structured reasoning baselines.On the traditional task Game of 24, eMoT achieves 100% accuracy, surpassing the baseline by up to 17.6%. Evaluations on mathematical task GSM8K, ASDiv, SVAMP, and MGSM further show consistent gains in multi-step mathematical reasoning. In our evaluation, we achieve superior performance despite utilizing a lightweight backbone model with constrained baseline capabilities. Compared to alternative methods that rely on massively scaled models, our results demonstrate that the performance gains are fundamentally driven by the eMoT framework's reasoning control rather than sheer model size.