A Principled Framework for Multi-View Contrastive Learning
A Principled Framework for Multi-View Contrastive Learning
Panagiotis Koromilas, Efthymios Georgiou, Giorgos Bouritsas, Theodoros Giannakopoulos, Mihalis A. Nicolaou, Yannis Panagakis
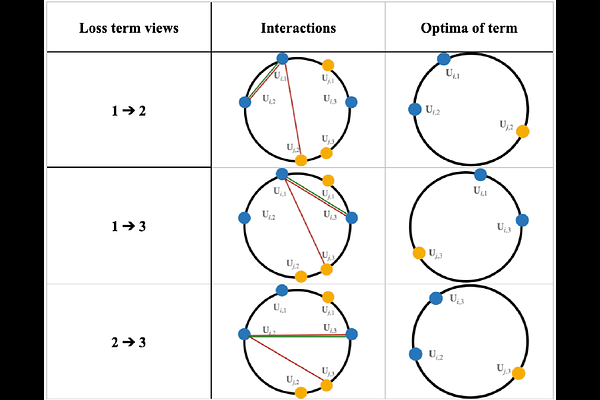
AbstractContrastive Learning (CL), a leading paradigm in Self-Supervised Learning (SSL), typically relies on pairs of data views generated through augmentation. While multiple augmentations per instance (more than two) improve generalization in supervised learning, current CL methods handle additional views suboptimally by simply aggregating different pairwise objectives. This approach suffers from four critical limitations: (L1) it utilizes multiple optimization terms per data point resulting to conflicting objectives, (L2) it fails to model all interactions across views and data points, (L3) it inherits fundamental limitations (e.g. alignment-uniformity coupling) from pairwise CL losses, and (L4) it prevents fully realizing the benefits of increased view multiplicity observed in supervised settings. We address these limitations through two novel loss functions: MV-InfoNCE, which extends InfoNCE to incorporate all possible view interactions simultaneously in one term per data point, and MV-DHEL, which decouples alignment from uniformity across views while scaling interaction complexity with view multiplicity. Both approaches are theoretically grounded - we prove they asymptotically optimize for alignment of all views and uniformity, providing principled extensions to multi-view contrastive learning. Our empirical results on ImageNet1K and three other datasets demonstrate that our methods consistently outperform existing multi-view approaches and effectively scale with increasing view multiplicity. We also apply our objectives to multimodal data and show that, in contrast to other contrastive objectives, they can scale beyond just two modalities. Most significantly, ablation studies reveal that MV-DHEL with five or more views effectively mitigates dimensionality collapse by fully utilizing the embedding space, thereby delivering multi-view benefits observed in supervised learning.