Controllable Generation of Artificial Speaker Embeddings through Discovery of Principal Directions
Controllable Generation of Artificial Speaker Embeddings through Discovery of Principal Directions
Florian Lux, Pascal Tilli, Sarina Meyer, Ngoc Thang Vu
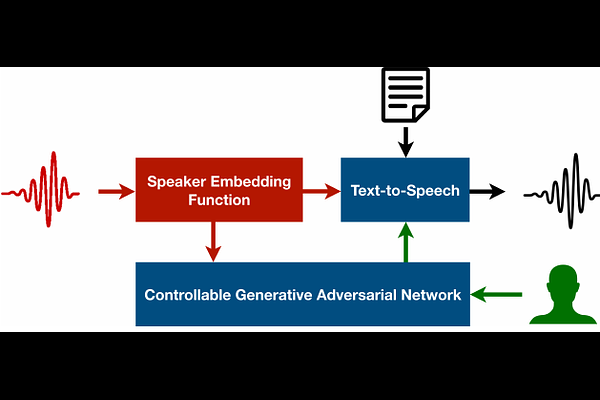
AbstractCustomizing voice and speaking style in a speech synthesis system with intuitive and fine-grained controls is challenging, given that little data with appropriate labels is available. Furthermore, editing an existing human's voice also comes with ethical concerns. In this paper, we propose a method to generate artificial speaker embeddings that cannot be linked to a real human while offering intuitive and fine-grained control over the voice and speaking style of the embeddings, without requiring any labels for speaker or style. The artificial and controllable embeddings can be fed to a speech synthesis system, conditioned on embeddings of real humans during training, without sacrificing privacy during inference.