MARVEL: Multi-Agent Reinforcement-Learning for Large-Scale Variable Speed Limits
MARVEL: Multi-Agent Reinforcement-Learning for Large-Scale Variable Speed Limits
Yuhang Zhang, Marcos Quinones-Grueiro, Zhiyao Zhang, Yanbing Wang, William Barbour, Gautam Biswas, Daniel Work
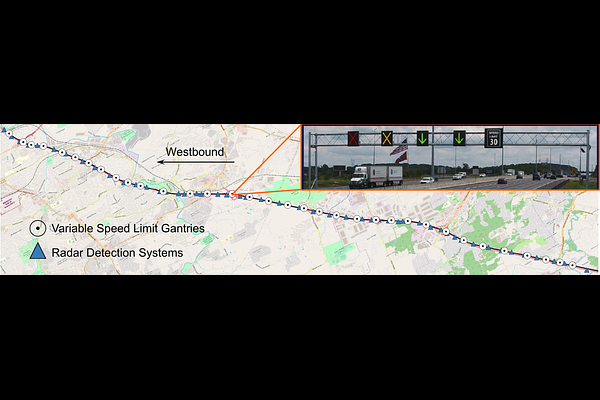
AbstractVariable speed limit (VSL) control is a promising traffic management strategy for enhancing safety and mobility. This work introduces MARVEL, a multi-agent reinforcement learning (MARL) framework for implementing large-scale VSL control on freeway corridors using only commonly available data. The agents learn through a reward structure that incorporates adaptability to traffic conditions, safety, and mobility; enabling coordination among the agents. The proposed framework scales to cover corridors with many gantries thanks to a parameter sharing among all VSL agents. The agents are trained in a microsimulation environment based on a short freeway stretch with 8 gantries spanning 7 miles and tested with 34 gantries spanning 17 miles of I-24 near Nashville, TN. MARVEL improves traffic safety by 63.4% compared to the no control scenario and enhances traffic mobility by 14.6% compared to a state-of-the-practice algorithm that has been deployed on I-24. An explainability analysis is undertaken to explore the learned policy under different traffic conditions and the results provide insights into the decision-making process of agents. Finally, we test the policy learned from the simulation-based experiments on real input data from I-24 to illustrate the potential deployment capability of the learned policy.