Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations
Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations
Yu-Hui Chen, Raman Sarokin, Juhyun Lee, Jiuqiang Tang, Chuo-Ling Chang, Andrei Kulik, Matthias Grundmann
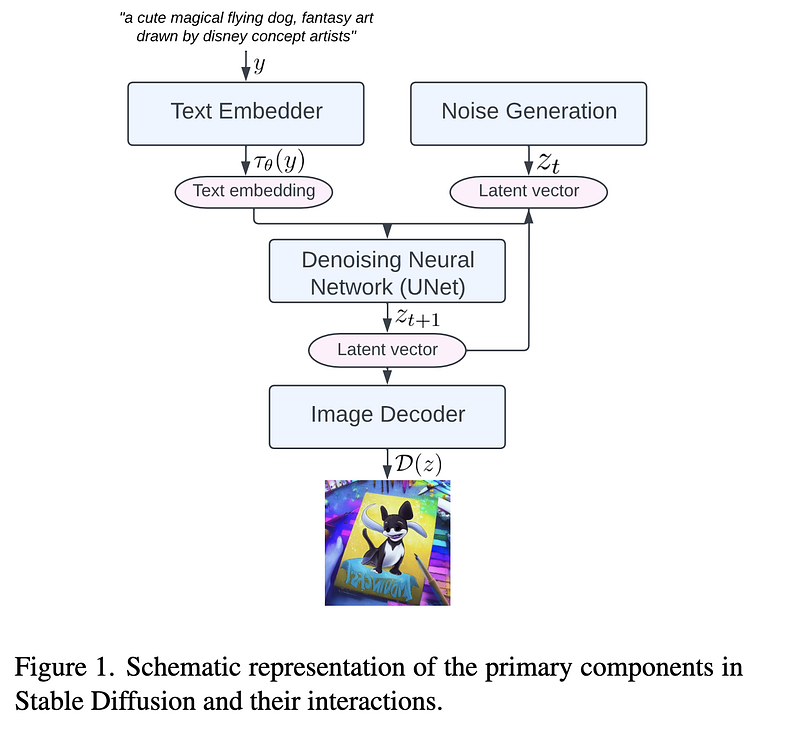
AbstractThe rapid development and application of foundation models have revolutionized the field of artificial intelligence. Large diffusion models have gained significant attention for their ability to generate photorealistic images and support various tasks. On-device deployment of these models provides benefits such as lower server costs, offline functionality, and improved user privacy. However, common large diffusion models have over 1 billion parameters and pose challenges due to restricted computational and memory resources on devices. We present a series of implementation optimizations for large diffusion models that achieve the fastest reported inference latency to-date (under 12 seconds for Stable Diffusion 1.4 without int8 quantization on Samsung S23 Ultra for a 512x512 image with 20 iterations) on GPU-equipped mobile devices. These enhancements broaden the applicability of generative AI and improve the overall user experience across a wide range of devices.