Plug n' Play: Channel Shuffle Module for Enhancing Tiny Vision Transformers
Plug n' Play: Channel Shuffle Module for Enhancing Tiny Vision Transformers
Xuwei Xu, Sen Wang, Yudong Chen, Jiajun Liu
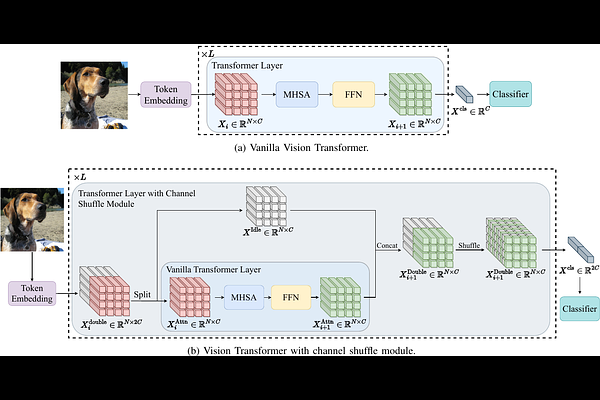
AbstractVision Transformers (ViTs) have demonstrated remarkable performance in various computer vision tasks. However, the high computational complexity hinders ViTs' applicability on devices with limited memory and computing resources. Although certain investigations have delved into the fusion of convolutional layers with self-attention mechanisms to enhance the efficiency of ViTs, there remains a knowledge gap in constructing tiny yet effective ViTs solely based on the self-attention mechanism. Furthermore, the straightforward strategy of reducing the feature channels in a large but outperforming ViT often results in significant performance degradation despite improved efficiency. To address these challenges, we propose a novel channel shuffle module to improve tiny-size ViTs, showing the potential of pure self-attention models in environments with constrained computing resources. Inspired by the channel shuffle design in ShuffleNetV2 \cite{ma2018shufflenet}, our module expands the feature channels of a tiny ViT and partitions the channels into two groups: the \textit{Attended} and \textit{Idle} groups. Self-attention computations are exclusively employed on the designated \textit{Attended} group, followed by a channel shuffle operation that facilitates information exchange between the two groups. By incorporating our module into a tiny ViT, we can achieve superior performance while maintaining a comparable computational complexity to the vanilla model. Specifically, our proposed channel shuffle module consistently improves the top-1 accuracy on the ImageNet-1K dataset for various tiny ViT models by up to 2.8\%, with the changes in model complexity being less than 0.03 GMACs.